

Lo spazio alla frontiera dell'AI è sempre più stretto
È difficile pensare che qualcuno possa scalzare il triumvirato composto da OpenAI, Anthropic e Google DeepMind. E, se dovesse accadere, non sarà certo per mano di un'azienda d'oltreoceano


IN POCHE RIGHE
Posto che se c’è una cosa che l’AI ci ha insegnato è che la rapidità con cui tutto evolve impedisce di fare previsioni con orizzonti più lunghi di un’ora1, uno dei pochi macro trend che pare stia emergendo è un certo consolidamento della frontiera.
L’idea che il mercato sia “winner takes all” (o anche solo “winner takes most”) è discussa, ma non una potenzialità remota. Tra i motivi per i quali si sta cercando speditamente di progettare sistemi in grado di automatizzare l’intero ciclo di ricerca e sviluppo AI e dunque automigliorarsi (il recursive self-improvement, RSI, di cui parliamo sovente) c’è proprio quello di guadagnare un distacco pressoché incolmabile per i competitor.
In un issue recente di Upload abbiamo parlato di Google — che tra una settimana esatta sarà sull’importante palco dell’I/O — come il lab con maggiore pressione addosso proprio riguardo al suo progresso in direzione RSI, benché paradossalmente il più attrezzato in termini di capitale (finanziario e umano) e infrastruttura, dalle TPU ai data center2.
Ma a farvi compagnia, sulla sommità della montagna sempre più spropositatamente grande dell’intelligenza artificiale, gli altri nomi restano solo due: Anthropic e OpenAI.
UNA STORIA
La notizia più interessante degli ultimi sette giorni è arrivata proprio da Anthropic, il cui annuncio con SpaceXAI è piovuto dal cielo come un proverbiale fulmine a ciel sereno. L’azienda di Dario Amodei prenderà in affitto tutto il data center Colossus di SpaceXAI — oltre 200k GPU3 — per training e inference di Claude, alleviando i dolori più immediati del compute crunch di cui soffre ormai da mesi ma mettendo in cascina anche una buona fetta di capacity per il futuro4 (benché lo stesso Elon Musk abbia confermato che l’azienda si riserva il diritto di revoca qualora alcuni termini dovessero cambiare).

Se per Anthropic la logica della trattativa era ed è piuttosto chiara, dall’altro lato sembrerebbe più rivelatrice. xAI (ora parte di SpaceX) è nata solo tre anni fa espressamente per fare concorrenza alla frontiera, con la solita forza battagliera di Musk. Tuttavia, dopo un momento intorno al lancio di Grok 2 in cui sembrava che il modello potesse legittimamente duellare con i rivali, il gap è progressivamente aumentato. Lo stesso Elon Musk, che in queste settimane si trova in tribunale dopo aver citato OpenAI in giudizio, ha dovuto ammettere che i suoi LLM, indietro nelle capability, hanno tenuto botta anche grazie alla distillazione proprio dei modelli — superiori — di OpenAI.5
Ciò ha confermato che Elon è straordinariamente capace quando si tratta di atomi: Tesla, SpaceX, Starlink e per certi versi anche la Boring Company sono tutte imprese legate largamente al mondo fisico in cui un visionario è riuscito a realizzare le sue idee, con feat non di rado straordinari6. Lo stesso Colossus, per testimonianza del CEO di Nvidia Jensen Huang, è stato un’opera mastodontica messa in piedi con velocità sorprendente: soli 19 giorni — diciannove! — dal concept alla fruizione, a fronte di tempistiche tradizionali che ruotano attorno all’anno per la sola execution. Non esistono molti umani sul pianeta in grado di fare accadere qualcosa del genere.
Eccezionalità che, però, non si trasferisce necessariamente nel software, nei bit, dove il genere di skillset necessario diverge ampiamente. La seconda cosa che il deal ha reso manifesta è che tutta quella capacity a SpaceXAI non serve, sia perché la domanda per Grok è verosimilmente molto bassa sia perché, a detta di Elon, il training dei prossimi Grok si è comunque spostato sul ben più imponente Colossus 27.
Monetizzare la capacità del primo sito prestando il compute ad Anthropic è dunque, senza dubbio, la mossa più economicamente ragionevole.
L’ACQUA IN CUI NUOTIAMO
Molti stanno leggendo questo fatto come un’ammissione tacita di resa. Non sarebbe semplice arguire il contrario, se non altro per un discorso di matematica dei tempi: Anthropic e OpenAI stimano che il recursive self-improvement sia distante giusto un paio d’anni, e uno spiraglio così stretto per chi già adesso si trova ad inseguire parrebbe veramente insufficiente per invertire il trend e spezzare il circolo virtuoso.
La partita, però, è ancora pienamente nel vivo, e dare qualcuno definitivamente per spacciato potrebbe rivelarsi altrettanto ingenuo. Senza contare l’infinito numero di startup che costruisce il proprio prodotto sui foundation model di altri — e che avrebbe un set di preoccupazioni dedicato — lo stuolo di lab “second tier” che lavora a modelli proprietari è folto e agguerrito. E non ha solo tutta l’intenzione di rimanere in scia, ma almeno l’ambizione per provare a vincere; anche giocando su tavoli diversi.
Esistono almeno quattro cluster che vale la pena mettere in luce.
1 — I runner-up diretti
La prima, lo abbiamo appena detto, è la stessa SpaceXAI. L’accordo per prestare Colossus ad Anthropic non è un’autocondanna a diventare una neocloud8, e l’azienda gode in ogni caso di una stack unica che potrebbe ripristinare il suo posizionamento in cima. Oltre ai foundation model (Grok) e i data center proprietari (Colossus), SpaceXAI ha anche in cantiere la produzione di chip con la Terafab e la distribuzione con Starlink; senza contare il deal da $60 miliardi per Cursor, con il quale si integrerebbero nel portfolio un prodotto con utilizzo reale e un team formidabile. Don’t count Elon out just yet, in pratica.
Poi c’è Meta, che dopo una serie di scivoloni piuttosto vistosi e la risultante campagna acquisti faraonica per accaparrarsi alcuni dei migliori talenti del mondo ha messo in piedi il suo Superintelligence Labs, guidato — bizzarramente — dall’ex-CEO di ScaleAI Alexandr Wang. Con il recente rilascio di Spark, primo modello della nuova famiglia Muse, Meta sembra quantomeno essere tornata in pista, più o meno allo stesso livello di SpaceXAI (cioè un gradino o due dietro la frontiera). Zuckerberg, come Musk, vorrà senza dubbio riprendere a dare del filo da torcere ai “big three”, e i $600 miliardi di capex messi sul tavolo da qui al 2028 porteranno probabilmente da qualche parte — difficile pronosticare da qui se l’automazione dell’R&D sia un obiettivo realistico, ma Spark è un segnale valido9.
2 — I “figliastri”
Un fenomeno affascinante riguarda i neolab nati come gemmazioni di OpenAI e DeepMind, nello specifico, con executive di assoluto rilievo che hanno preferito staccarsi e seguire la propria strada anziché continuare a guidare i propri team dentro le organizzazioni.
Da OpenAI sono nati SSI di Ilya Sutskever (ex Chief Scientist) e Thinking Machines Lab di Mira Murati (ex CTO)10; a cui si è aggiunto Core Automation lanciato da Jerry Tworek, tra le altre cose responsabile del primo modello reasoning in assoluto (o1).
La storia di DeepMind è lunga, come lo è la lista di talenti entrata ed uscita da lì. Ci sono dozzine di startup finanziate dai VC che contano alumni GDM tra le loro C-Suite. Le più importanti — o quantomeno le più note e finanziate — sono però tre: Ineffable Intelligence di David Silver (ex reinforcement learning lead), Recursive Superintelligence dell’ex Principal Scientist Tim Rocktäschel, e Reflection AI dei ricercatori Misha Laskin e Ioannis, del team fondatore di DeepMind.
Ciò che accomuna tutti e sei gli esperimenti è, al momento, proprio l’essere fortemente sperimentali: le loro valutazioni già multimiliardarie si sostengono principalmente sui ai nomi che portano i founder, ma la giovane età dei lab (molti hanno meno di due anni; alcuni solo pochi mesi) e le difficoltà di approvvigionamento di compute stanno tenendo a porte chiuse quasi ogni forma di avanzamento tecnologico vero e proprio11.
3 — Gli outsider
Ognuno dei lab qua sopra potrà ragionevolmente contare su tecniche segrete di avanzamento dei sistemi, ma nessuna parrebbe aver apertamente indicato la volontà di distaccare il cuore delle proprie attività dal paradigma dominante, che vede alla base enormi modelli linguistici addestrati con algoritmi di gradient descent su tecnologia transformer.
Ci sono invece almeno tre esempi illustri che sembrano voler guardare altrove sin dal principio:
Advanced Machine Intelligence (AMI), la startup che l’ex Chief Scientist di Meta Yann LeCun — tra i “padrini” dell’AI e vincitore anche del Turing Award — ha fondato nel 2025, è nata proprio dalla “scissione culturale” col gigante della Silicon Valley. Se Meta era rimasta indietro è anche perché LeCun si è sempre detto scettico sugli LLM, contestando l’idea che il linguaggio da solo fosse sufficiente a raggiungere un’intelligenza realmente generale. AMI viaggia in direzione contraria.
Pensiero analogo è quello di Fei-Fei Li, celebre docente di computer science a Stanford, il cui World Labs è altrettanto focalizzato sul connubio tra intelligenza digitale e modellazione spaziale, per percepire, ragionare de e interagire con il mondo in tre dimensioni.
Il passo da qua alla robotica è facile, e tra i lab più promettenti rientra senza dubbio Hark di Brett Adcock, CEO anche di Figure, che lavora su robot umanoidi. Adcock e il suo team vedono le due come facce alternate della stessa medaglia, asserendo che l’AI necessiti di interazioni col mondo reale attraverso l’hardware più che il software. Device, dunque, che si tratti di interfacce human-first (per le persone) o appunto robot autonomi e intelligenti dalla forma umana.
4 — Gli hyperscaler
Rimangono infine gli altri hyperscaler, Amazon e Microsoft, che giocano però un’altra partita. Forti dei loro investimenti iniziali — in Anthropic la prima e in OpenAI la seconda — entrambi i giganti si sono cullati sul fatto che la loro funzione chiave non giustificasse una spesa ingente per garantirsi la piena autosufficienza. I foundation model che hanno sviluppato, rispettivamente Nova e MAI, non sono né hanno mai avuto la pretesa di essere combattivi12, e il loro ruolo rimane ancora pienamente infrastrutturale grazie ad AWS e Azure. A differenza di qualche anno fa ciò che è cambiato è che gli accordi non sono più esclusivi: OpenAI ne ha uno fino a $100 miliardi con AWS, spalmato su otto anni (incluso l’utilizzo dei chip Trainium per addestramento e inferenza), mentre Anthropic ha firmato per acquistare da Redmond $30 miliardi di compute, che assicureranno la presenza di Claude su tutte le piattaforme Microsoft negli anni a venire.
Escludendo Nvidia, che costituisce una linea trasversale di “banca dell’AI”, l’unica Mag7 rimasta è Apple, tenutasi pressoché del tutto fuori dalla corsa. Complice anche l’arrivo del nuovo CEO John Ternus, dal forte background nell’hardware, la scommessa di Cupertino sarà “semplicemente” quella di posizionarsi di nuovo come layer di riferimento per quanto riguarda i dispositivi su cui l’AI si usa, puntando molto più sull’edge che sul cloud13.
PERCHÉ CONTA
Se per gli hyperscaler esiste una condizione per la quale il buildout infrastrutturale può comunque risultare vincente, per la miriade di lab secondari la scommessa appare più ardita. Considerando però che chi li guida conosceva e conosce molto bene l’ambiente dall’interno, la scelta di staccarsi dal corpo principale (OpenAI, DeepMind) per fondare un’unità autonoma è anche una concessione implicita del fatto che, magari per vie traverse, una possibilità concreta di raggiungere gli obiettivi finali — un sistema di RSI prima e un’AGI poi — ci sia, al netto dei contorni da Davide contro Golia. Il tempo che hanno per dimostrarlo, va da sé, non è moltissimo, e la pressione del mercato inizierà presto a stare loro col fiato sul collo.
Come dicevamo all’inizio, nell’intelligenza artificiale più che mai non esistono però certezze, e questa mappatura è più una panoramica logica dello status quo che la descrizione di un binario a senso unico per il futuro. Allo stesso tempo, però, ignorare che le traiettorie visibili siano quelle e pensare che grandi spiragli siano ancora aperti parrebbe quantomeno ingenuo.
Discorso differente, invece, è quello di tutte le dozzine di startup di terza fascia (e oltre), la cui value proposition sembra veramente appesa a un filo, poiché in lotta per una serie di risorse sempre più scarse e ambite (talento e compute), e senza un vantaggio intrinseco precedentemente acquisito in altri punti della stack, come nel caso degli hyperscaler.
SCENARI
Non sfuggirà agli occhi dei più attenti che, dalla rassegna sopra, oltre ai modelli cinesi (che necessiterebbero di un capitolo a parte) manca completamente l’Europa. Mistral, l’unico lab del vecchio continente, non offre modelli competitivi da alcun punto di vista, e non è proprietario di alcuna tecnologia unica o rilevante.
Guardando la leaderboard generale dell’Artificial Analysis index, il primo modello europeo tra i presenti è Mistral Medium 3.5 (rilasciato ad aprile scorso), il cui punteggio lo piazza diciannovesimo, relegandolo a una crescente irrilevanza. L’idea che l’Europa possa in qualche modo tornare in gara — figurarsi ambire alle posizioni di punta — appare mestamente risibile.
Non è un demerito di Mistral, che ha anzi il nobile pregio di esistere. La triste verità è che i presupposti per competere non sono mai stati realmente presenti; negli USA e in Cina sono il risultato di decenni di affastellamento delle risorse, non un insieme di mosse indovinate dopo il lancio di ChatGPT. Vedere l’Europa assente in quella o altre classifiche non dovrebbe stupire nessuno.
Ma se la sfida sul piano dei modelli non esiste, ciò che sconcerta maggiormente è che anche il piano infrastrutturale appare ben poco competitivo: all’interno della stessa UE, un progetto di espansione di appena €20 miliardi14 viene giustamente criticato, perché non si capisce bene né chi né come avrebbe modo di utilizzare i cluster che verrebbero costruiti (non si sa in che tempi, ovviamente).15
Nicoleta Kyosovska, una ricercatrice del think tank Centre for European Policy Studies di Bruxelles, ha ricordato a Politico che “non abbiamo molte aziende di AI” che sarebbero in grado di sfruttare in modo realmente concorrenziale quel piccolo blocchetto infrastrutturale. “Abbiamo solo Mistral.”
Concentrarsi sui data center, tuttavia, potrebbe essere una mossa sensata per i cittadini e le imprese europee. Si farebbe pace con l’incontrovertibile subalternità agli Stati Uniti come situazione reale pregressa e si cercherebbe di costruire capacità strategica in altre parti della stack, non i modelli, l’harness o il compute — a patto, naturalmente, di riuscire a farlo su scala.
In una lettera ripresa dal Financial Times, i CEO di svariate aziende tech europee (ASML, Nokia, Airbus, SAP, Siemens, Ericsson, la stessa Mistral) hanno espressamente chiesto ai policymaker incentivi alla mobilità e possibilità di investimento del capitale privato, per allentare la cintura regolatoria corrente e provare ad allocare le risorse nel modo più efficiente possibile, pur consci della forchetta già enorme e in costante allargamento rispetto agli USA.
Quelle stesse regole che, come spesso accade, si ritorcono anche contro chi le ha congegnate: dal boom del 2022 l’Unione Europea si è principalmente occupata di confezionare l’AI Act e cercare di tenere a bada i modelli americani cianciando di “sovranità digitale” (quando già allora si sapeva che le regole, pur sane nei principi, non fossero del tutto lungimiranti). Ora che sistemi come Claude Mythos stanno mostrando — qui ed ora — quanto grande sia l’importanza di avervi accesso per fortificare le proprie difese digitali ed impedire ad attori avversi di bucarle con conseguenze catastrofiche, l’ironia potrebbe essere quella di dover passare leggi per obbligare quelle aziende a fornirlo (o, peggio, pregarle dietro le quinte).
Nel loro eccellente paper “Radical Optionality”, i giuristi Christoph Winter e Charlie Bullock offrono l’interpretazione più sagace e spiazzante del divario. Con un’immagine che, curiosamente, si appoggia all’altra parte del mondo (traduzione mia):
“Le rispettive traiettorie delle industrie tecnologiche europea e statunitense nel corso degli ultimi decenni sono come qualcosa di uscito dritto da un romanzo di Ayn Rand; risvegliano il medesimo istintivo senso di sbigottito disdegno nel cuore dell’osservatore libertario di uno scatto dal satellite della penisola coreana di notte.”
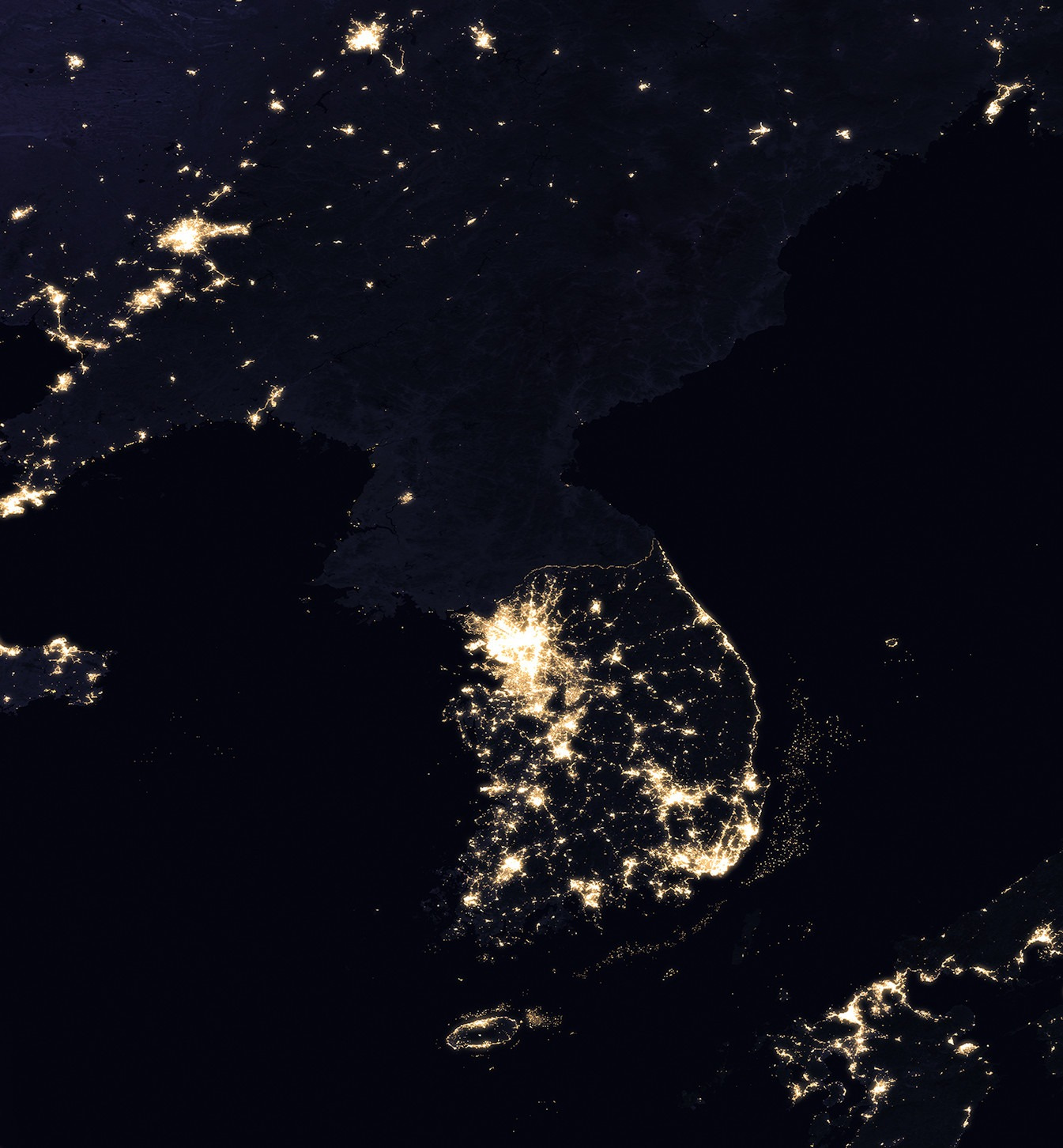
L’Europa, come i lab di seconda fascia, non è integralmente senza speranza; ma il suo posto non è la frontiera, da cui sarà più e più dipendente. Esistono altri ambiti adiacenti e complementari su cui fare leva16, ma ignorare la realtà del mondo là fuori non è più possibile: farlo, lo abbiamo già detto, potrebbe essere seriamente rischioso in termini di sicurezza nazionale. È il momento di farvi i conti, oltre le favole.

Come quando OpenAI ha deciso di spegnere Sora e avvisare Disney, con cui aveva un contratto da $1 miliardo, solo mezz’ora dopo…
Così tanta che può permettersi di rinunciare ad una parte e darla in affitto ad Anthropic.
Le stime parlano di 220.000 GPU (300 megawatt di compute), divise tra circa 150mila H100, 50 H200 e tra le 20 e le 30k unità di GB200, i chip Nvidia più nuovi disponibili (Blackwell).
OpenAI è stata a lungo considerata incauta per i suoi copiosi investimenti iniziali, ma la domanda di compute esplosa da inizio anno grazie alle nuove capacità agentiche dei modelli sembra aver dato loro pienamente ragione. Un grosso vantaggio su Anthropic, costretta a racimolare “avanzi” un po’ ovunque.
Una pratica che, come abbiamo raccontato, è più comune tra i modelli cinesi per mancanza di compute. Il caso di xAI è l’esatto opposto.
Non scordiamoci che stiamo parlando della persona il cui team lancia razzi nello spazio e poi li rende riutilizzabili dopo averli letteralmente acchiappati con delle mega pinze meccaniche!
…per il quale il punto di partenza supera le 500.000 GPU e l’obiettivo si attesta a ben 1 milione (!)
Business che, con la fame di compute, senza dubbio potrebbe comunque contare come una vittoria, più nel medio-lungo termine.
Un altro modello della famiglia Muse dovrebbe essere dietro l’angolo.
Questi due più il risultato delle scissioni interne a OpenAI — e le conseguenti insanabili rotture — che progetti nati spontaneamente, verrebbe da dire.
Eccezion fatta per Thinking Machines Lab, che oltre a Tinker ha appena annunciato io suoi nuovi "interaction model”.
Solo recentemente Microsoft sembra aver riorganizzato la divisione interna capitanata dall’ex fondatore di DeepMind Mustafa Suleyman per dare maggiore spinta ai frontier model.
La posizione di Apple è al tempo stesso più complessa e precaria di così, ma questa overview è sufficiente per lo scopo di questo numero.
Una goccia quasi insignificante in un oceano che dall’altra parte dell’Atlantico parla di $500 miliardi per la sola Stargate di OpenAI, circa $350 miliardi di accordi per Anthropic o i $600 di Meta, sia pure spalmati su orizzonti più lunghi.
Data center che, ça va sans dire, sarebbero pieni zeppi di GPU dell’americanissima Nvidia.
Oltre la sola ASML, si intende; un incentivo in più per consolidare le relazioni transatlantiche, non lasciare che vadano ulteriormente in malora!
⇑