

Anthropic e OpenAI accelerano. Google non ha più tempo per stare a guardare
La generazione di modelli in arrivo, come Claude Mythos e GPT "Spud", segna un ulteriore stacco nella corsa di frontiera all’intelligenza artificiale generale. Ora Google è chiamata a rispondere


IN POCHE PAROLE
Se la corsa all’intelligenza artificiale generale (AGI) risulta così frenetica, in buona parte è dovuto all’elevata competizione. L’assioma che sottende la frenesia parla di un vantaggio incolmabile per chi dovesse arrivare a un sistema robustamente generale, la cui manifestazione più elementare si avrebbe nel momento in cui dovesse riuscire a migliorarsi da sé.
È l’automiglioramento ricorsivo, il recursive self-improvement (RSI) di cui abbiamo fatto menzione le scorse settimane; il prossimo checkpoint ben visibile nel mirino dei lab. I risvolti del tagliare per primi il traguardo sono tutto fuorché ben delineati, e Upload si spinge per provare a spostare la discussione, dal fantascientifico all’ipotetico al reale — al potenzialmente imminente. Continuiamo a dirlo: è già tardi.
I concorrenti non mancano, ma esiste una solida prima linea che ad ora appare ben più (e meglio) attrezzata verso il raggiungimento dell’orizzonte. Si parla, naturalmente, di OpenAI, Anthropic e Google. xAI di Elon Musk e il Superintelligence Labs di Meta occupano una posizione più arretrata, benché non del tutto fuori dai giochi; i maggiori lab cinesi — come DeepSeek, Moonshot, Z.ai e Alibaba — sono anch’essi pienamente in corsa, ma con un gap ancora significativo, complice anche l’intervento dell’Amministrazione americana sugli export control dei chip Nvidia.
Di OpenAI e Anthropic si parla continuamente: tra modelli, IPO in arrivo, ARR e valutazioni roboanti, affiliazioni politiche non certo timide e uno scontro più o meno diretto tra le due, le prime pagine palleggiano tra l’una e l’altra.
Google, confusamente, sembra esserci e non esserci.
UNA STORIA
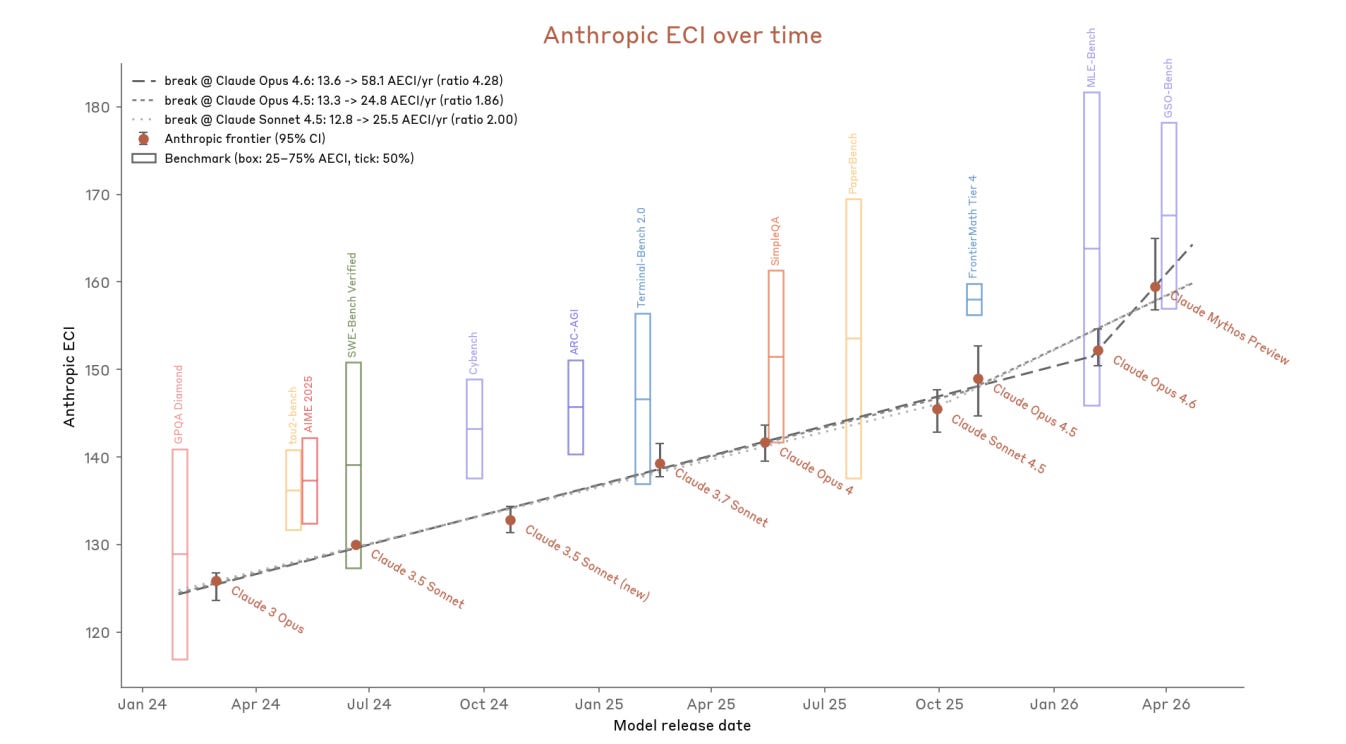
Claude Mythos, lo abbiamo raccontato nell’ultima newsletter, ha rappresentato uno spartiacque; un modello dalle capacità così dirompenti da non poter essere pubblicamente rilasciato è un evento, i cui effetti immediati ne hanno validato la serietà. È altresì incombente il prossimo modello di OpenAI, dal nome in codice “Spud”, le cui caratteristiche dovrebbero attestarlo nella medesima classe — il presidente di OpenAI Greg Brockman, ai microfoni del Big Technology Podcast di Alex Kantrowitz, ha parlato di Spud come un nuovo foundation model che dovrebbe “portare a fruizione due anni di ricerca”.
Quali che siano le specificità di Spud, la traiettoria seguirà la ripida ascesa delle capability; Mythos non sarà reso disponibile al di fuori di Project Glasswing, inizialmente, ma Spud potrebbe avere un destino difforme e le dinamiche della corsa di cui sopra imporranno comunque ad Anthropic di rilasciare modelli Mythos-class dopo non troppo tempo. Gli altri seguiranno a ruota.
Si sta dunque espandendo la finestra di Overton, sia per i toni della narrazione — gli scontri col Pentagono e gli allarmi lanciati dai capi delle banche centrali dei Tesori USA e UK — sia per l’utilizzo crescente dei sistemi agentici, che hanno chiaramente già mostrato un primo step change qualitativo rispetto ai chatbot degli scorsi anni. L’evoluzione da “pappagallo stocastico” a “just another business tool” è stata indubbiamente rapida; il passaggio successivo — sia pure tentativamente frenato, tra incomprensioni e puro denial — si sta concretizzando adesso.
Chi mastica intelligenza artificiale da un po’ sa che le previsioni circa l’entità del suo impatto sono da tempo state preconizzate come trasformative — a detta di molti, per intenderci, più vicine alla scoperta del fuoco che alla Rivoluzione Industriale — ma è solo di recente che la realtà dei sistemi da GPT-3.5 in poi ha reso imperativo iniziare a disegnarne meglio i contorni. Proprio il CEO di Anthropic Dario Amodei, autore dell’ormai celebre saggio “Machines of Loving Grace”, ha imposto l’immagine di un futuro a portata di mano dove l’esistenza di “un Paese di geni in un data center” ci imporrebbe riconfigurare gli strati più profondi della civiltà moderna.
Qualcuno, come più recentemente il candidato Democrat newyorkese Alex Bores — osteggiato da molti big della Silicon Valley, da a16z a Palantir e OpenAI — sta fortunatamente iniziando a provarci in un contesto più visibile. Ma se il post-AGI è un mistero (e un problema di policy incredibilmente complesso anche solo da inquadrare), il percorso per arrivarci è esso stesso pieno di incognite.
L’ACQUA IN CUI NUOTIAMO
Il cammino più promettente parrebbe quello tracciato da Anthropic, che vede nel coding la via più efficace ed efficiente per giungere a sistemi in grado di automigliorarsi. Un commitment che ha indubbiamente già dato i suoi frutti, costringendo OpenAI a cedere quote importanti del mindshare e dell’adozione dei prodotti, soprattutto nel campo enterprise.
OpenAI, forte del suo vantaggio iniziale e di finanziamenti imponenti, aveva provato a diversificare il portafoglio prodotti; in parte per cercare nuovi canali di introito, certamente, ma almeno in alcuni casi per moltiplicare le chance di breakthrough tecnologici, percepiti come essenziali per raggiungere un’intelligenza solidamente generale.
Sono tuttora in molti ad essere diffidenti sul fatto che l’architettura dell’AI mainstream odierna — modelli linguistici basati sui transformer e dosi di compute sempre più massicce — sia quella che porterà alla finish line. Esperimenti come Sora, l’iniziativa OpenAI for Science (chiusa questa settimana) o le incursioni nella robotica avrebbero infatti dovuto aiutare OpenAI a sviluppare un cosiddetto “world model” — un “modello del mondo” più comprensivo, basato su forme di esperienza eterogenee, oltre il ragionamento per-token, superando i limiti intrinseci che la compressione epistemica tramite il solo testo imporrebbe.
La scelta di ricondurre tutto al coding potrebbe dunque avere due spiegazioni, egualmente valide: la prima, più banale, è che tutti gli altri sforzi sono tremendamente costosi e, sebbene incoraggianti, di fatto non sostenibili per aziende in perdita costante e cospicua. L’altra, tanto self-serving quanto apparentemente corretta, è che quella strada sta funzionando: Mythos e (probabilmente) Spud raggiungono nuove vette anche grazie al “vecchio trucco” delle scaling law, continuando cioè ad ammassare dati e compute su cluster sempre più grandi in run di pretraining ormai ciclopiche; e il reinforcement learning sul codice fa il resto. Il muro chiamato a gran voce dagli scettici sembra essere del tutto inesistente; i risultati parlano da sé.
E Google?
È in questo framework che la posizione di Google appare disorientata e rivelatrice al tempo stesso.
Dopo una partenza in sordina con le prime versioni di Gemini, DeepMind ha indubbiamente recuperato terreno fino ad imporsi stabilmente nel trio di frontiera già con l’arrivo di Gemini 2.5 nel giugno di un anno fa. Con Gemini 3 Pro a novembre, per qualche settimana, il modello di Mountain View sembrava essere addirittura il sistema di punta indiscusso; il 3.1 Pro disponibile oggi, pur avendo perso la leadership assoluta, è al pari di GPT-5.4 e Claude Opus 4.7 (uno la spunta in un benchmark, l’altro in un test differente, etc.).
I presupposti per un avanzamento concorrenziale ci sono, insomma; ma due aspetti riguardanti la strategia di Google emergono come parzialmente irrisolti.
Il primo è che, a differenza di Anthropic ed OpenAI, DeepMind gode di fondi (capitale da bruciare) e risorse (compute) virtualmente illimitati, alimentati dalla macchina stampa-soldi di Google. È inoltre l’unico lab che opera su una stack quasi integralmente proprietaria, dai chip (che sono le sue TPU e non le GPU di Nvidia, usate da tutto il resto della industry) fin su ai modelli.
Il secondo ne è una diretta conseguenza: Demis Hassabis ha più volte ripetuto come per giungere all’AGI sia verosimile che alcuni nuovi breakthrough siano necessari, motivo per cui DeepMind si avvale di molteplici sistemi di AI oltre ai soli LLM. Da Genie per la modellazione in tempo reale di ambienti 3D interattivi a GenCast per le previsioni meteo, passando per il noto AlphaFold (per la struttura delle proteine), AlphaGeometry (modello fine-tuned per le Olimpiadi di Matematica), AlphaChip (per aiutare a progettare chip AI dedicati), Imagen e Veo (generazione immagini e video), e tutta una serie di altri mattoncini che, se messi insieme, dovrebbero fornire al cervello artificiale di Google una comprensione più ricca della realtà.
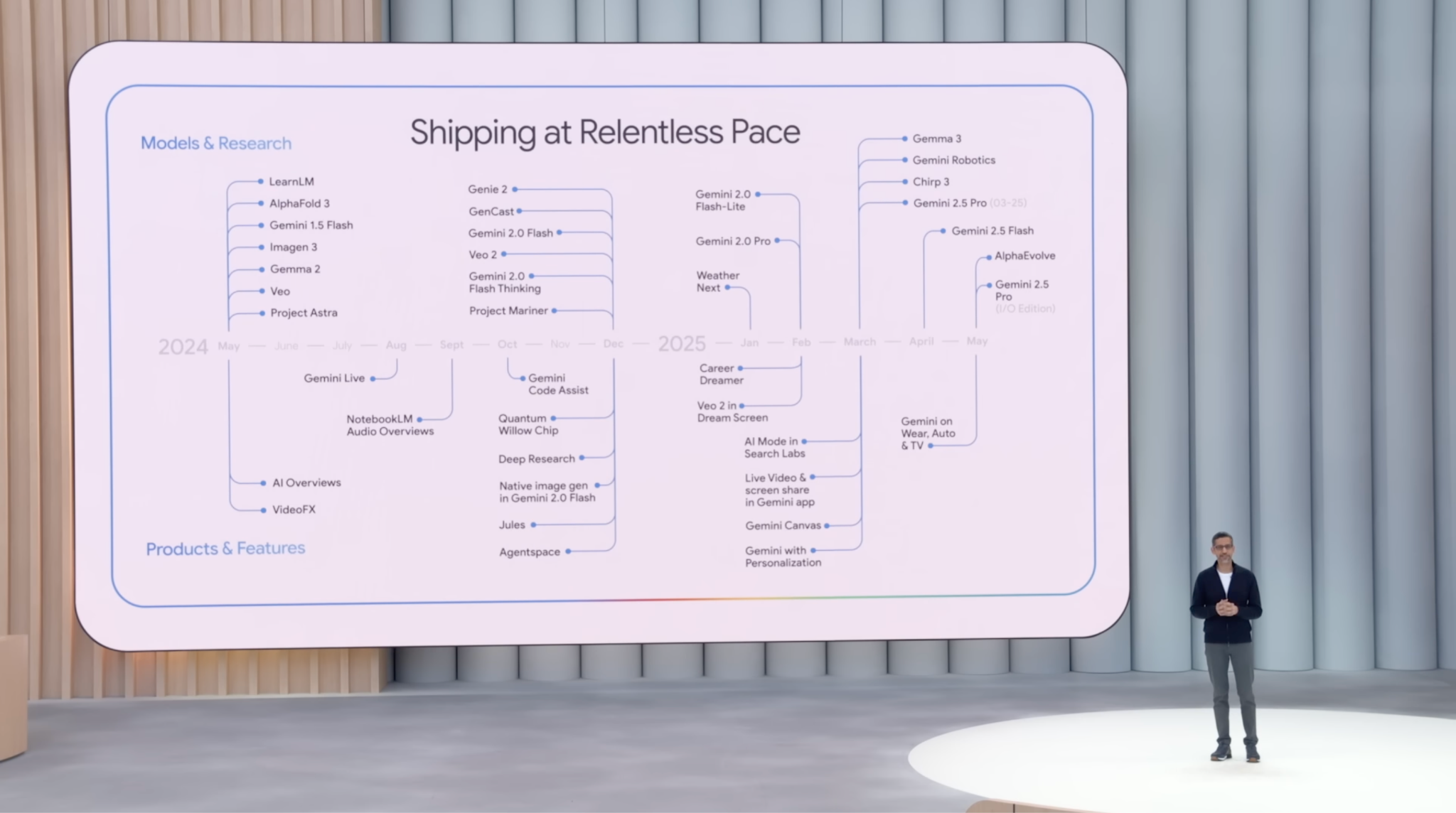
Il sentiero verso l’AGI di Google parrebbe dunque avere le sembianze di un accerchiamento convergente, partendo da più fronti, e non di una linea retta incentrata sul coding. Ma la scommessa è giusta?
PERCHÉ CONTA
Proprio sul coding Google sembrava quasi aver consciamente mollato la presa. Il prodotto dedicato che dovrebbe competere con Claude Code e Codex, Antigravity, ha un’adozione miserrima; e la stessa famiglia Gemini performa mediamente peggio dei modelli di OpenAI e Anthropic sui coding task.
Ancor più di questo, però, c’è la pressoché totale assenza di prodotti agentici, che sembrerebbero suggerire che Google non vi abbia pensato come veicolo primario (o comprimario) di evoluzione della sua AI — forte, si penserebbe, che sarebbe l’approccio multi-tentacolare a dover tracciare la rotta.
Un report di The Information di ieri ha svelato invece che, con un memo interno fatto circolare niente meno che da Sergey Brin, Google avrebbe formato uno “strike team” insieme al CTO Koray Kavukcuoglu per migliorare esattamente le capacità di Gemini nel codice e nei compiti agentici, e colmare così il gap con Claude e ChatGPT nell’ottica di automatizzare la ricerca AI e raggiungere più velocemente l’RSI, riconosciuto come milestone fondamentale.
Potrebbe essere un’ammissione simile a quella di OpenAI, per cui il vettore studiato da Anthropic è quello più spedito — nel memo, Brin scrive senza mezzi termini che gli ingegneri di Google dovranno sentirsi “obbligati” ad usare gli agenti per i task più complessi, cercando di dare il via ad un circolo virtuoso per alzare prima di tutto i numeri interni di Gemini1. Anche coloro che dentro DeepMind già usano gli agenti si appoggiano spesso a Claude, infatti, e pare che la proposta di rimuoverne l’accesso sia stata respinta con forza dentro l’organizzazione.
Che questa sia l’unica via corretta resta da vedere, e non è affatto escluso che i vantaggi competitivi di Google non possano risultare comunque cruciali in un secondo momento; se non da un punto di viabilità tecnica, sicuramente da uno di deployment (poter servire modelli complessi a miliardi di utenti in tutto il mondo) ed efficienza economica (poterlo fare a prezzi ragionevoli), dove il gigantesco vantaggio infrastrutturale permetterebbe a Google di distribuire i suoi sistemi futuri senza incorrere negli inevitabili colli di bottiglia che Anthropic sta già affrontando — e che, finché pezzi importanti di Stargate non saranno pronti, potrebbero colpire anche OpenAI.
Il tempo, però, non giocherebbe a suo favore.
SCENARI
Nel mondo di Mythos e Spud, se Google vuole continuare ad essere competitiva (come indubbiamente Demis Hassabis e tutta la leadership intendono, a partire da Sergey Brin), deve portare alla luce qualcosa di nuovo — e deve farlo ora. Una versione di Gemini che migliora “semplicemente” qualche benchmark rischierebbe di essere “just another business tool”, e dunque non più sufficiente.
Fra un mese esatto, l’azienda avrà a disposizione il suo palcoscenico più grande, la conferenza annuale I/O, per ricatapultarsi nel top-of-mind di chi lavora e ragiona già sull’AI del domani. In ogni caso, avrà l’imperativo di mostrare una direzione chiara, e gli scenari che si aprono sono sostanzialmente due.
Google potrebbe limitarsi ad introdurre un modello appena competitivo, concentrandosi piuttosto su un’ulteriore espansione orizzontale e nuovi esperimenti più vicini alla sua suite di prodotti corrente — da Android a Chrome all’offerta hardware, passando per Workspace e gli altri servizi adiacenti, come l'accordo con Apple, per cui i prossimi Foundation Model dentro e fuori Apple Intelligence si appoggeranno a Gemini.
Ciò non deporrebbe bene; non tanto perché un sistema di nuova generazione che non mostra nemmeno in minima parte i vantaggi apportati dagli altri sistemi di AI vorrebbe dire che un moat competitivo non c’è, ma che il tempo per farlo giungere a maturazione non è sufficiente. Rimanere poi indietro anche sul coding, sugli agenti e sulla qualità dell’harness, come il campanello suonato dal memo di Brin insinuerebbe, sarebbe un ulteriore colpo difficile da incassare. Il gap diverrebbe pericolosamente più ampio.
L’alternativa è che il relativo silenzio degli ultimi mesi sia stato una strategia voluta precisamente per utilizzare la cassa di risonanza dell’I/O per mostrare non solo di poter legittimamente continuare ad aspirare a competere con Mythos, Spud e la nuova generazione di modelli — che si tratti sempre di un LLM basato sui transformer o qualcosa di nuovo e diverso — ma di muoversi sulla pista facendo leva su un bacino di prodotti proprietario che tutti gli altri lab faticherebbero enormemente a replicare (figuriamoci a replicare nei tempi). Lasciando loro la speranza che la strada del coding rimanga un’alternativa valida fino alla fine.
A febbraio, il CFO Anat Ashkenazi aveva dichiarato che Google scrive con l’AI circa la metà del proprio codice, mentre l’executive alla guida di Claude Code, Boris Cherny, aveva già detto un mese prima che “praticamente il 100%” di quanto prodotto dagli ingegneri di Anthropic viene dallo stesso Claude.
⇑
Chiarissima grazie. Sottolineo la scelta di Google di mettere come primo appuntamento all'I/O proprio lo speech sulle novità AI di Google: scelta dettata da voler seguire il trend o ha davvero delle novità? staremo a vedere con curiosità.